
how not to run a sAAs company
Founder Mode. Somewhere someone said something and a meme was born.
This one is a bit too long with bit too much satire.
The idea was to find a reason to create a billion sqlite databases. I found a reason but the best I got to was a few million. You can play with the project but I won't say what it is. There is a silly AI gimmick in there too for good measure.
I have less than 2 weeks left to continue the "Founder Mode" life before I must take off the "founder" mantle, a mantle with as much meaning as Agile and NFT but certainly more meaning than AI.
2 weeks should be more than enough time to spin up at least one highly lucrative sAAs company if not 2. Excuse me, "AI" powered sAAs company. What is AI powering? I don't know yet. But it will power something.
Step one is to do a little SEO research to see what kind of product the market doesn't know it wants yet.
in search of alpha
There are many SEO tools for market research. Ahref and semrush are two big quality players but big quality also means big $.
All I want to do is run a backlink search for a few popular existing AI products. I plan on copying one of them wholesale, opensource and all. Big plus if it already uses shadui, cursor, and openai on the network's edge. Backlinks will give me a good idea on how and where my target entered the market at. Did they only use SEO hacks or did they run some influcencer ads too? Maybe they only targeted one country and not another. It isn't only about copying the product but also the go to market too.
Sadly, Semrush's lowest saaS tier is $140/m and Ahrefs' lowest tier is $130/m. That seems like an awful lot to run a few hundred maybe thousand backlink queries but it does include many other SEO features I don't need.
Clearly, purchasing either product is not an option.
While I do need to find alpha and find it fast, it would be worth standing up a simple backlink api to save on costs. An api, if you will, where one can input a domain and get a pithy little backlink report with the ability to filter down specific urls. Simple enough. What could possibly go wrong?
Before building anything, what is a backlink anyway?
backlinks, the real seo
In the world of big search energy there are many factors which help one page rank over another: tags, metadata, opengraph data, page performance, and more. They all help but what REALLY counts are how many other "reputable" domains link to your page. The more backlinks a website has the more honest it looks.
This makes sense as the more people who point to content and say, "this is good" the more likely the content is good. Bonus points if the coolest kids say so but who are the coolest kids? It is a bit of a chicken and the egg problem as to be a cool kid you need reputable domains to say you are cool but then how do said domains become reputable?
It doesn't matter what wizardry is used as backlinks are the glue which binds the internet and the best urls are positively dripping in high quality backlinks or so the SEO experts would want us to know.
The anatomy of a backlink is pretty simple. Any <a> tag with an href that points to an external domain. It can be useful to pull other metadata off like what the anchoring text is, should a search engine follow the link, meta tags on the source page, etc.
An example
Link Source: https://old.reddit.com/r/cats
Link Target: https://jenginblog.dev/muffins-ate-my-grandmas-chair
Link Anchor Text: My cat muffins ate my grandmas chair
Link Follow: yes
The more backlinks there are which point to jenginblog.dev, the better the domain is ranked.
Easy, so how are backlinks found?
the worlds fastest web crawler
Backlinks are found by crawling the entire internet and parsing all the links on all the pages into a truly "webscale" database. While writing an internet scale web crawler sounds like fun I have a mission and a deadline.
Taking a lesson from the AI world it would be worth leveraging the Common Crawl project. A project which crawls the internet every month or so and stores the results in a few different formats. The most recent crawl is pretty recent at the time of writing. This will work.
The WARC file format is for web page archiving and will have the html to parse. There are about 70k compressed gigs across 90k files to process for the most recent crawl. Luckily, after searching the docs it turns out that common crawl already parses links out of the html and includes them in a lighter WAT format. This is only a little over 16 tb. Much better. Even better, the formats should support streaming which means the whole file doesn't need to be downloaded at once.
This should skip the whole crawler and html parsing steps.
sqlite is webscale
The idea for indexing potentially trillions of backlinks is simple. Squeeh stack on a digital ocean VPS.
I know what you are thinking. How can sqlite store a trillion rows in a single db? It can't (or can) but it also doesn't have to. I have another idea.
Something like this
backlinks/
├── com/
│ └── www/
│ └── www.example.com.sqlite
├── ai/
│ └── jack.ai.sqlite
└── org/
└── info/
└── info.example.org.sqlite
The idea is to have one db file per domain which has all the backlinks that target said domain. These files could be stored in a single folder or nested in some format. I read about file system limits and in theory one should be able to have a billion files in one folder. Beyond that and you need a custom filesystem like the one Google built.
I decided to break files up by top level domain and then by subdomain to make it a little easier to understand. There are other ways to format the folders but this will work for now.
Most websites do not have millions of backlinks but it would be worth keeping limits in the back of my mind. I don't care about how many backlinks social media websites have more so the other direction.
The schema for this is simple.
backlinks (
source TEXT,
target TEXT,
source_title TEXT,
is_nofollow BOOLEAN,
anchor_text TEXT,
crawl_date DATETIME
);
I don't expect this setup to scale to trillions of backlinks but it should be good enough for billions, not in a single databse but spread across many files. The majority of links point to a few popular websites likely in an 80%-20% breakdown. Limiting a domain to a max of 50m backlinks should cut down hundreds of billions of backlinks I don't care about. I think twitter alone has some 50b backlinks which I absolutely don't care about. Add Meta, Instagram and Tikok, you get the picture.
Even then, sqlite is single threaded and not great for this kind of workload. Duckdb would be a wiser option but it would be interesting to see how sqlite does.
Time to spin up prototype.
python, not even once
Let's be clear. Python is not my second nor third or fourth language. However, it has what seems to have the best library and documentation for working with these web archive file formats using warcio. The demos for the library are decent too. Getting a working example with the above logic didn't take too long with a little gyptiy help.
I will skip over the helper functions and focus on the streaming part.
def stream_wat_paths():
response = requests.get(f"{COMMON_CRAWL_BASE_URL}/crawl-data/CC-MAIN-{COMMON_CRAWL_INDEX_DATE}/wat.paths.gz", stream=True)
if response.status_code == 200:
with gzip.GzipFile(fileobj=BytesIO(response.content)) as gz:
for line in gz:
yield line.decode('utf-8').strip() # Decode and strip each line
else:
print(f"Failed to fetch WAT paths: {response.status_code}")
def process_common_crawl_data(start_index, end_index):
for index, wat_file in enumerate(stream_wat_paths()):
print(f"Processing file: {index}--{wat_file}")
url = f"{COMMON_CRAWL_BASE_URL}/{wat_file}"
response = requests.get(url, stream=True)
if response.status_code == 200:
payload = io.BytesIO(response.content)
for record in ArchiveIterator(payload):
source_url = record.rec_headers.get('WARC-Target-URI')
crawl_date = record.rec_headers.get('WARC-Record-Datetime')
source_domain = urlparse(source_url).netloc
# narly parsing code and bad data checks
metalinks
links = {}
for link_data in metalinks:
if 'url' in link_data and 'text' in link_data:
target = link_data['url'].strip()
anchor_text = link_data['text']
if not is_valid_url(target):
continue
target_domain = urlparse(target).netloc
if target_domain != source_domain and link_data['path'] == 'A@/href':
links[target] = {
'source': source_url,
'source_title': get_value(metadata, ['Head', 'Title'], ''),
'is_nofollow': link_data.get('rel', '') == 'nofollow',
'anchor_text': anchor_text,
'crawl_date': crawl_date
}
for target in links.keys():
target_domain = urlparse(target).netloc
db_path = get_db_path(target_domain)
# upsert db
initialize_database(db_path)
if os.path.exists(db_path) and get_backlink_count(db_path) > MAX_RECORDS_PER_DB:
continue
The idea is to gather all the links on a page and then insert them into the correct sqlite database file based on the target domain. This means multiple database files will need to be updated per page processed.
This worked exactly as it should have once some logic was added to handle bad data. Sometimes an expected field would be missing or an href would be invalid. I decided to filter out anything that had a port, raw ip, or invalid url.
More controversially, I filter out anything that is not https. Yes, if it doesn't use https I don't care about it. If it doesn't have that s, it is dead to me. Target and source both must be https. Other protocols are fine such as app deeplinks but if it starts with http it must be https.
It works and after running some data look who it is.
Now, I know what you are thinking. Did I seriously test this in vscode? Yes, and it was not happy when I opened the com folder. No idea why.
I tested this at 1.5m domains locally. It took good old find . -type f | wc -l minutes to run. Pulling the top websites by backlink count was interesting to say the least and matched pretty close to what other sources claim.
./datastore/com/facebook/www/www.facebook.com.sqlite: 6070795
./datastore/com/twitter/twitter.com.sqlite: 4839141
./datastore/com/instagram/www/www.instagram.com.sqlite: 3526914
./datastore/com/blogger/www/www.blogger.com.sqlite: 2682323
./datastore/com/youtube/www/www.youtube.com.sqlite: 2631516
./datastore/com/linkedin/www/www.linkedin.com.sqlite: 1479920
./datastore/com/google/www/www.google.com.sqlite: 1063620
./datastore/com/pinterest/pinterest.com.sqlite: 695891
./datastore/org/wordpress/wordpress.org.sqlite: 679151
./datastore/com/whatsapp/api/api.whatsapp.com.sqlite: 650014
./datastore/com/google/policies/policies.google.com.sqlite: 509382
./datastore/com/shopify/www/www.shopify.com.sqlite: 480154
./datastore/com/instagram/instagram.com.sqlite: 456226
./datastore/com/github/github.com.sqlite: 453112
./datastore/me/t/t.me.sqlite: 452857
The performance leaves something to be desired.
I started to calculate how long it would take to process all 90k WAT files with the current setup and I think it exceeded the heat death of the universe. The problem was clearly that this was single threaded and not python.
I asked gyptiy to make it multi-threaded and to my great surprised, it worked.
Now, the problem lent itself to multi-threading as you can simply have a thread process a given file and let sqlite and the file system handle locks. The issue here is while it does work and I can see all the threads doing stuff.
This is the interesting bit.
def process_common_crawl_data(start_index, end_index):
wat_files = [wat_file for index, wat_file in enumerate(stream_wat_paths()) if start_index <= index < end_index and wat_file.endswith('.wat.gz')]
with ThreadPoolExecutor(max_workers=NUM_THREADS) as executor:
futures = {executor.submit(process_wat_file, wat_file): wat_file for wat_file in wat_files}
for future in as_completed(futures):
wat_file = futures[future]
try:
future.result() # This will also raise if there's an exception on a worker thread
except Exception as exc:
print(f"{wat_file} generated an exception: {exc}")
It spins up a ThreadPoolExecutor, whatever that is, and then does what I think is a list comprehension to get a bunch of futures which I assume is some async handle like a promise in js land. I had a different idea for multi-threading this in bash launching multiple scripts with a start and end index as args. I think each python script would have a runtime overhead so this is better.
One issue with AI'ing something like this up is that it makes me feel like I understand it all but I don't. And I need to keep aware of that.
The multithreaded version is much faster but still so so slow. Not heat death of the universe slow but slow.
Activity Monitor was illuminating. First there were thousands of these processes called mds_store running.
It turns out it is spotlight trying to index the hundreds of thousands of folders the script is creating. That is simple to fix but also shouldn't happen on a server. Once, fixed, the cpu useage dropped down significantly.
The network was almost inactive but the disk was getting hammered with 18k write ops/s or so. Not much data but many writes. This is expected as after each page the processed backlinks are written to disk which ends up being many small writes. It would be better to batch the write as much as possible to avoid opening and closing files.
I guess python has a defaultdict which made gathering all the links for a file before writing pretty easy. However, all the threads are writing at the same time and step on eachother causing file locks. It isn't much faster.
After many hours profiling I found that python's sqlite driver is about 100x slower for bulk writes than raw sqlite3 or bunjs's sqlite driver. I don't know why. It should all be the same native code. Sqlite is also about 100x slower than appending to a csv file which does makes some sense. You can guess where this is going.
Keep the python script which streams the WAT files and saves valid links to a csv file in a tmp folder. But use bun and javascript to do the rest.
I tried to stay in python land I really did but I was too slow at writing it. Don't worry this will bite me later when I try multi-threading on bun. Try being the prejorative here.
Before moving to js land I made some updates to the python script.
This is the important part.
def process_common_crawl_data(start_index, end_index):
result_queue = queue.Queue(20)
wat_files = [wat_file for index, wat_file in enumerate(stream_wat_paths()) if start_index <= index < end_index and wat_file.endswith('.wat.gz')]
writer_threads = [threading.Thread(target=write_backlinks_to_csv, args=(result_queue,)) for _ in range(NUM_CONSUMER_THREADS)]
for t in writer_threads:
t.start()
with ThreadPoolExecutor(max_workers=NUM_THREADS) as executor:
futures = {executor.submit(process_wat_file, wat_file, result_queue): wat_file for wat_file in wat_files}
for future in as_completed(futures):
wat_file = futures[future]
try:
future.result()
except Exception as exc:
print(f"{wat_file} generated an exception: {exc}")
for _ in range(NUM_CONSUMER_THREADS):
result_queue.put((None, None))
for t in writer_threads:
t.join()
It now uses the producer consumer pattern with a queue per the suggestion of a friend. It is tiny bit faster than the gypity code and a bit more flexable but otherwise pretty much the same.
Testing this script showed it would take about 10 days to process the common crawl dataset on a medium sized vps. That is cutting it tight but doable.
We all know that go and rust would be far better languages to use. As a matter of fact this little lad has a great write up on parsing it all in a day for $60 bones. Slick.
bun, just the once
The next step is to pipe the backlinks in the tmp folder into the right sqlite databases based on the backlinks target domain.
The simple but fast solution is to load all the backlinks into memory bucketed by target domain and then save each domain's backlinks to disk in one write op. This is not possible without about a tb of ram which isn't impossible but outside my vps budget.
A baseline is to bucket by target domain per file like the earlier python version before flushing to disk. This would also lend itself to multi-threading.
However, the overhead of opening and closing sqlite connections is still orders of magnitute slower than appending to a csv file. This is expacted as sqlite adds a bit of overhead vs appending a bit of data.
Doing two passes will give the best of both worlds. One pass buckets into csv files to keep writing fast. Then another would convert the csv files into a sqlite database.
The process would something like this.
Step 1: python stream and extract WAT
root/
├── tmp/
│ ├── python-processed-backlink-csv-files01.csv
│ ├── python-processed-backlink-csv-files02.csv
│ ├── python-processed-backlink-csv-files...
│ └── python-processed-backlink-csv-files_N.csv
└── datastore/
Python will stream the raw WAT archive files and extract out the backlinks into csv files.
Step 2: bun buckets by backlink target domain
root/
├── tmp/
│ └── DELETED
└── datastore/
├── com/
│ └── www/
│ └── www.bigqueryenergy.com.csv
├── ai/
│ └── jack.ai.csv
└── org/
└── info/
└── info.example.org.csv
Bun will read the tmp files and bucket into datastore based on the domain. Optionally, the files in tmp can be deleted now or later.
Step 3: bun converts csv to sqlite
root/
├── tmp/
│ └── DELETED
└── datastore/
├── com/
│ └── www/
│ └── www.bigqueryenergy.com.sqlite
├── ai/
│ └── jack.ai.sqlite
└── org/
└── info/
└── info.example.org.sqlite
Bun will finish it off by converting the csv files into sqlite databases. Nice.
A singled threaded baseline was created by processeing one file at a time before writing to disk and it looked ok. It can bucket about 6.8k backlinks/s. Not fast enough though.
What is interesting is that the cpu is doing nothing but the disk is also doing...almost nothing. What gives?
The majority of domains have a single backlink per file. This tends to be high in write ops but low in data throughput. This can be confirmed by processing more files before writing to disk but memory is not unlimited. Flushing backlinks once ram usage goes up is a solution.
And it is a bit faster.
flushing 213348 domains processed 1277919 backlinks
processing file tmp/CC-MAIN-20240802234508-202408
processing file tmp/CC-MAIN-20240802234508-202408
processing file tmp/CC-MAIN-20240802234508-202408
processing file tmp/CC-MAIN-20240802234508-20240€
flushing 141919 domains
processed 1913086 backlinks
processed 12 files in 212.447s
That is about 9k backlinks/s. However, disk IO still isn't great. This version was counting by domain and flushing everything once it was over 200k domains.
A better idea is to instead count by backlink and flush the domains with the most backlinks to reduce the number of file writes.
function flushBacklinks(flushCount = BACKLINK_FLUSH_SIZE) {
console.log(`flushing backlinks`);
const sortedDomains = [...backlinkMap.keys()].sort(
(a, b) => backlinkMap.get(b).length - backlinkMap.get(a).length
);
let i = 0;
let count = 0;
while (flushCount > 0) {
if (i >= sortedDomains.length) break;
const domain = sortedDomains[i];
const saved = flushDomainToDisk(domain);
flushCount -= saved;
count += saved;
i++;
}
console.log(`saved ${count} backlinks`);
}
This gave a solid bump in speed.
processing file tmp/CC-MAIN-20240802234508-20240803024508-
processing file tmp/CC-MAIN-20240802234508-20240803024508-
flushing 269055 domains
processed 1913086 backlinks
1913086 backlins across 12 files in 147.247s
Now it is at 13k backlinks/s. I found that by tweeking the number of backlinks flushed made a large difference.
processing file tmp/CC-MAIN-20240802234508-20240803024508-00011-warc.wat
flushing backlinks
saved 100086 backlinks
flushing backlinks
saved 1308724 backlinks
1913086 backlins across 12 files in 81.655s
This is now at 23.3k/s by flushing 100k backlinks rather than 250k as before. This makes sense as at the end 1.3m backlinks are saved likely each with only a few backlinks.
On one thread this would take about a week to process a common crawl dataset. It is worth noting this process can run against partial data so it wouldn't have to wait for the python script to download everything before starting.
Multi threading would be the next step.
After spending way too much time running into memory issues with promises and a recursive folder function I got it working but sadly bun was not working.
Bun v1.1.18
Args: "bun" "run" "backLink-worker," "sqlite"
Elapsed: 276ms | User: 188ms
sys: 206ms
RSS: 99.35MB Peak: 99.35MB Commit: 1.07GB Faults: 70
panic: Segmentation fault at address 0x0
oh no: Bun has crashed. This indicates a bug in Bun, not your code.
To send a redacted crash report to Bun's team, please file a GitHub issue using the link below:
All kinda of random segfaults. Workers are experimental but I cannot help but wonder of zig is the real problem.
When it does run the IO throughput is great but it always ends up crashing which corrupts files. Single threaded is still fast enough so it is fine.
Since the csv files could be larger than memory they are streamed in and pushed to the sqlite database in batches. The database schema is the same as before.
CREATE TABLE IF NOT EXISTS backlinks (
id INTEGER PRIMARY KEY AUTOINCREMENT,
source TEXT NOT NULL,
target TEXT NOT NULL,
source_title TEXT,
is_nofollow BOOLEAN,
anchor_text TEXT,
crawl_date DATETIME
);
Don't worry about indexes. I didn't and surely it will not come to haunt me in the future.
reduce, reuse, recyle
Spinning up an api shouldn't take long. A get request to a /backlink endpoint with a few query params for filtering. It will return backlink count, unique domains count, popular urls, popular domains, and popular anchor text with filter options.
Bun with hono are already on the VPS so using them for the api is obvious. Here it is with the verbose parts omitted.
export const useBacklinks = (app: Hono) => {
app.get("/backlinks", async (c) => {
const domain = c.req.query("domain");
const target = c.req.query("target");
const source_domain = c.req.query("source_domain");
const anchorText = c.req.query("anchor");
// create filters
if (!isSafePath(domainPath, outputPath) || !existsSync(outputPath)) {
console.error("db file not found for", outputPath, domainPath);
return c.json({ error: "Database file not found" }, 404);
}
const db = new Database(outputPath);
try {
// queries
return json;
} catch (error) {
console.error(error);
return c.json({ error: "Database query failed" }, 500);
} finally {
db.close();
}
});
};
Parse any query params and then make sure the domain exists and is valid. Then run some queries and done. Sqlite blocks the main thread which means a slow query well prevent processing other requests. A version which has a worker pool does improve throughput but seg faults pretty quick if there are too many requests.
It would be a good idea to toss a cache on the requests and the internet told me nginx can do it easily.
And so it can.
location /backlinks {
proxy_cache my_cache;
proxy_cache_valid 200 30m;
proxy_cache_valid 404 1m;
expires 30m;
add_header X-Proxy-Cache $upstream_cache_status;
proxy_pass http://localhost:3000;
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection 'upgrade';
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
proxy_cache_bypass $http_upgrade;
}
To be clear, gypity wrote this up and it looked right to me but didn't work and that is because you need to define where the cache lives.
proxy_cache_path /var/cache/nginx levels=1:2 keys_zone=my_cache:10m max_size=1g inactive=60m use_temp_path=off;
And now it works.
{
"backlink_count": 36099,
"nofollow_count": 1765,
"last_crawl": "https://www.facebook.com/sharer/sharer.php?t=c10-3&U=http&3A%2F%2Fedostripe.com%2Fc10-3",
"unique_linking_domains": 18815,
"topTargetUrls": [{
"url": "https://www.facebook.com/sharer/sharer.php?src=sdkpreparse&U=https%3A%2F%2Fdevelopers.facebook.Com%2Fdocs%2Fplugins%2F",
"backlinks": 100
}, {
"url": "https://www.facebook.com/officialstackoverflow",
"backlinks": 89
},
...etc
}
On subsequent requests the api isn't hit which means the cache works. Awesome.
Adding this to a VPS is pretty easy since it uses the same squeeh stack as a previous project. A dry run of the processing scripts went without issue.
Great.
Before scaling up for a full scrape it would be wise to validate the largest range my VPS can handle. This ends up being about 2% of the common crawl dataset. The limit is not processing but storage and wow is the ocean expensive on that front.
Each WAT archive file results in about 40mb of backlinks uncompressed. There are 90k files in the dataset. That would be about 3.6tb. This would cost about $360/month with DO block storage oof. With a 50m backlink limit per domain I imagine the number would be much smaller.
To get a more accurate read I will process a full 2% and see what the file size of all the sqlite dbs are. If it ends up being a dead end, I will abandon this and just pay ahref or semrush.
While the scripts process common crawl into sqlite databases it would be nice to have a dashboard to make using the api a little nicer.
To keep in the spirit of "founder mode" I think v0.dev should be used to create the dashboard. After using up free credits this is what I was left with.
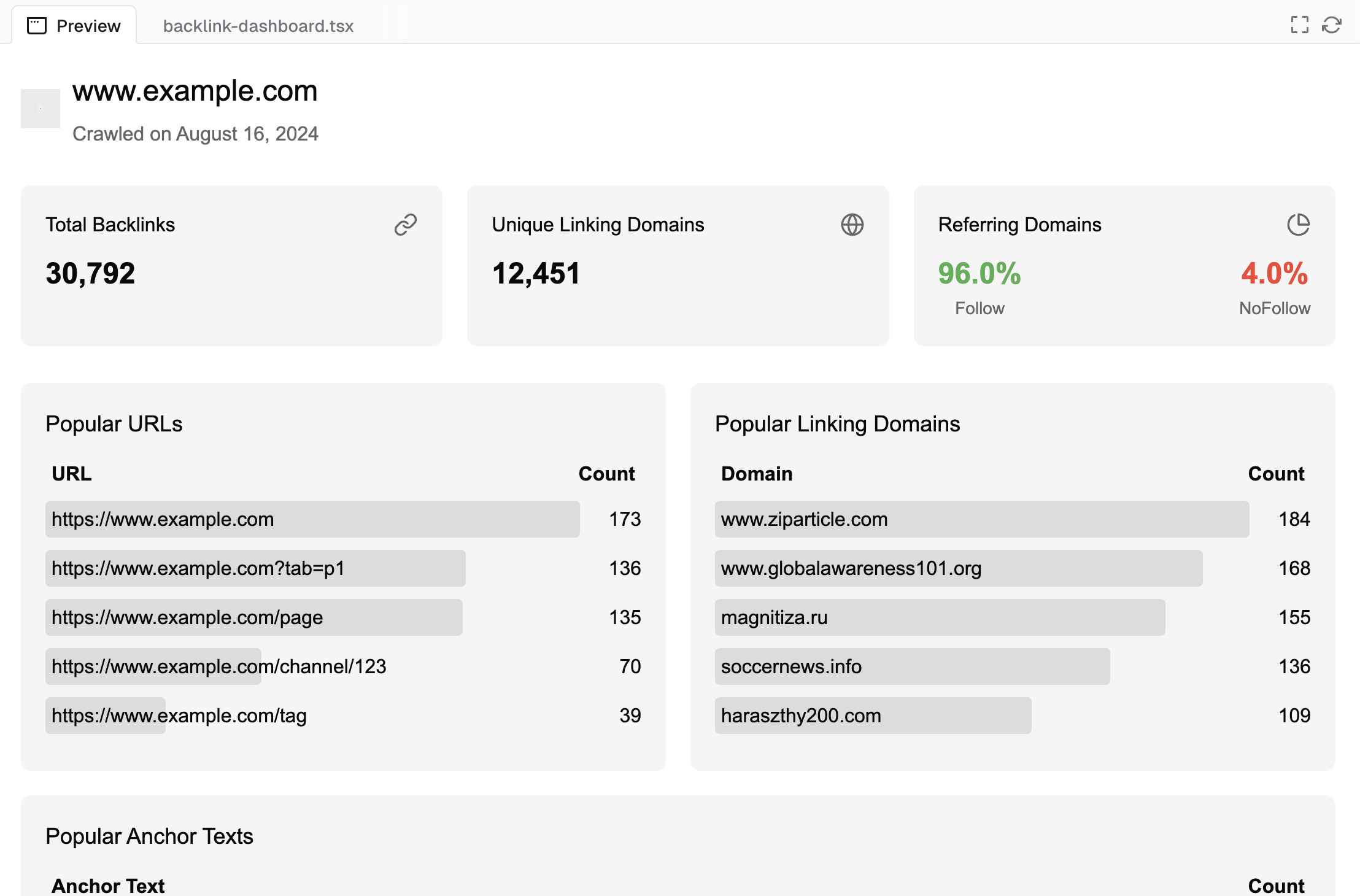
The output is ok but the code will not work. No worries, nothing a bunch divs with a heavy helping of css tossed in a nextjs mixer can't fix.
Nextjs supports a feature called ISR which is basically the same as that nginx cache added earlier but ISR sounds way cooler. Enabling this feature is pretty simple. Just export the revalidation time from your page.
export const revalidate = 3600;
Why should there be multiple layers of almost identical caching? I don't know but caching things make me feel fast and edgy.
One downside of running nextjs with ISR locally is that often you want to bust the cache between code changes but it doesn't bust. You get the same page. So you end up having to bounce the app or update the revalidate time to something smaller. Maybe there is a setting I missed but it makes local ISR a bit of a pain.
Here is the finished dashboard running locally.
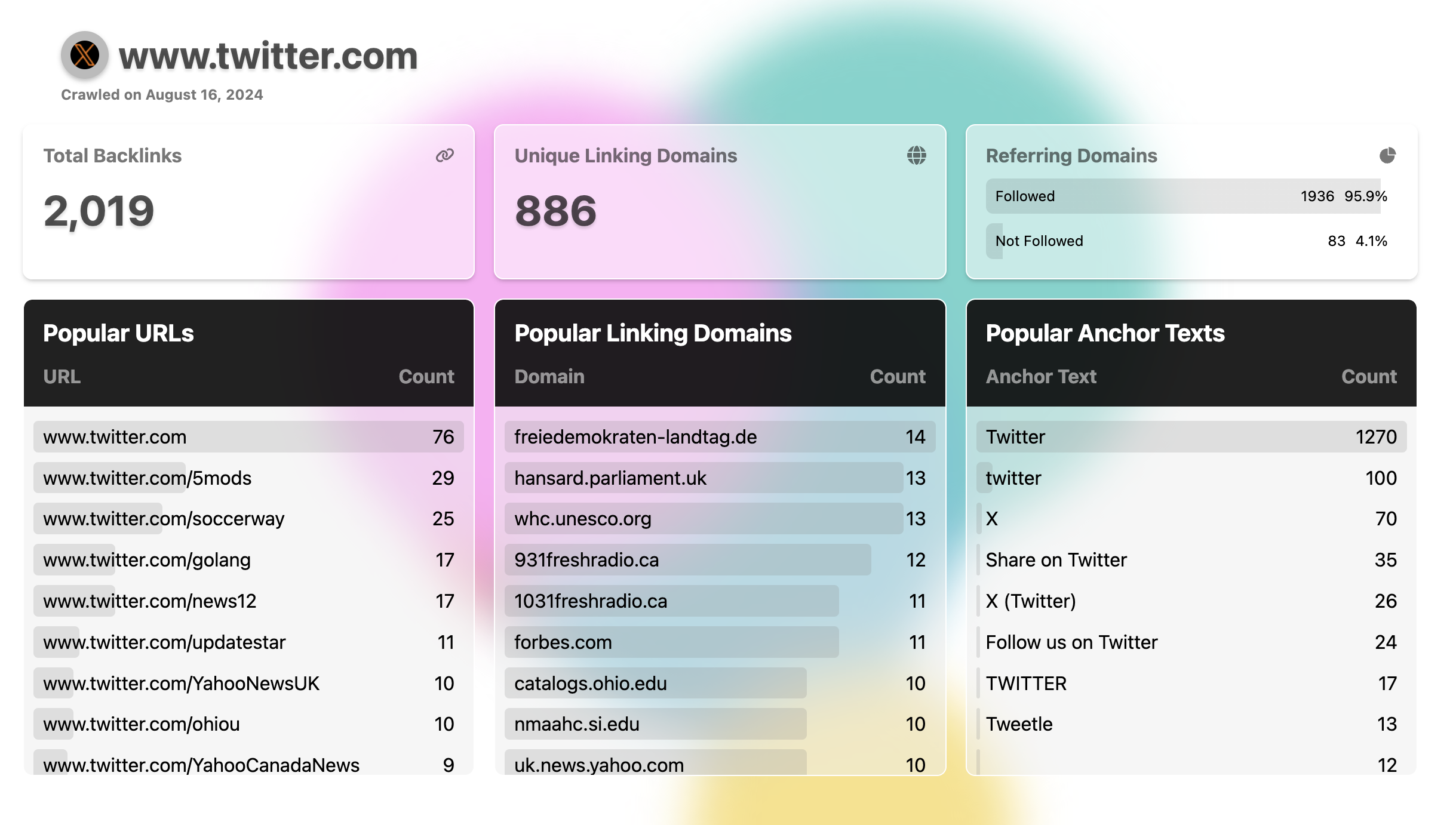
I think it is about 20% better than the earlier v0 version which makes it worthwhile.
Cool, time to check in on that VPS.
panic at the disco
The results were not good. Like really not good. It is too much data and too slow.
The problem is the data isn't compressed. Using duckdb and parquet files would be a smart move but god damn I won't give up on the squeeh stack. Not now. Not after everything we've been through.
Part of the issue is that a sqlite database file has overhead and the majority of websites only have a few backlinks. It takes around 50 backlinks for the overhead to become negligible. Adding indexes will only make it worse.
It seems like it is time to simply pay ahred or semrush. But there is another more pressing problem.
It has been like 10 days and I am not much closer to a profitable AI SaaS company than when I started.
What now?
I spent the day reading every Paul Grahm book, article, comment, and tweet I could get my hands on and then took a good long hard look in the mirror. And then it hit me, the answer, it was in front of me the whole time.
Backlinks.
super-mecha-founder-godzilla-mode
There is no way to compete with ahref or semrush in terms of quality nor scale. However, I don't need to. All I need to do is out last them. If every $1 I spend costs them a $1,000, that is a trade I will make every day, $365,000/year, every year, forever. It isn't about making money, it is about winning. Last one standing. Go.
Still, giving away backlink search for 2% of the internet may not be useful enough. It needs more oomph and I know just the feature.
2% of the internet's backlinks indexed and aggregated should be more than enough information for an LLM to provide outstandingly valuable and impactful insigts. It will be called "agentic intelligence". Perfect. I can see the $ now.
It is important to understand the damage caused to the competition. This will be calculated based on the number of subscriptions the compitition loses. After some digging, I found that most competing backlink search products will give 5 or so free requests per day before hitting a paywall at about $135/month. Sometimes more, sometimes less.
This means if someone does more than 5 requests in a day, that month would count a lost subscription. Would the person have purchased a $135 sub? Unlikely, but I am counting it anyway.
This metric is live, public, and can be found here.
Am I grossly over estimating the damage? Not at all. A search is only counted if it wasn't already cached. Go ahead. Reload the page. Swipe back and forward. No double counts. No nickle and diming here. 100% quality product guarentee. Take that Algolia.
The product needs a name. I decided on lunk as it sounds a bit like the fun dumb cousin of a link.
The logo? Obvious.
And with that lunk is almost feature ready. There are 3 items left and I have 3 days left before the "founder" engery is gone for good.
- Payment - Slap a slipery Stripey boy in there
- Agentic intelligence - Add a LLM prompt card somewhere
- Optimize - Make backlink search api better
finance please leave the room now
Stripe. What is it? What does it do? Why is it worth billions. I don't know. But I know how payments will work for lunk. There will be no user sign up or user database at all. Pure as god intended. Instead, Stripe will do all the heavy lifting.
The subscription button opens a tab to a Stripe standalone payment page. When the purchase is complete, have Stripe call a webhook which will use Stripe's api to cancel/refund the subscription. The $ isn't as interesting as the data. Anytime someone would have signed up is a strong signal the service is causing "major damage" to the compitition.
So a slinky Stripe integration is needed.
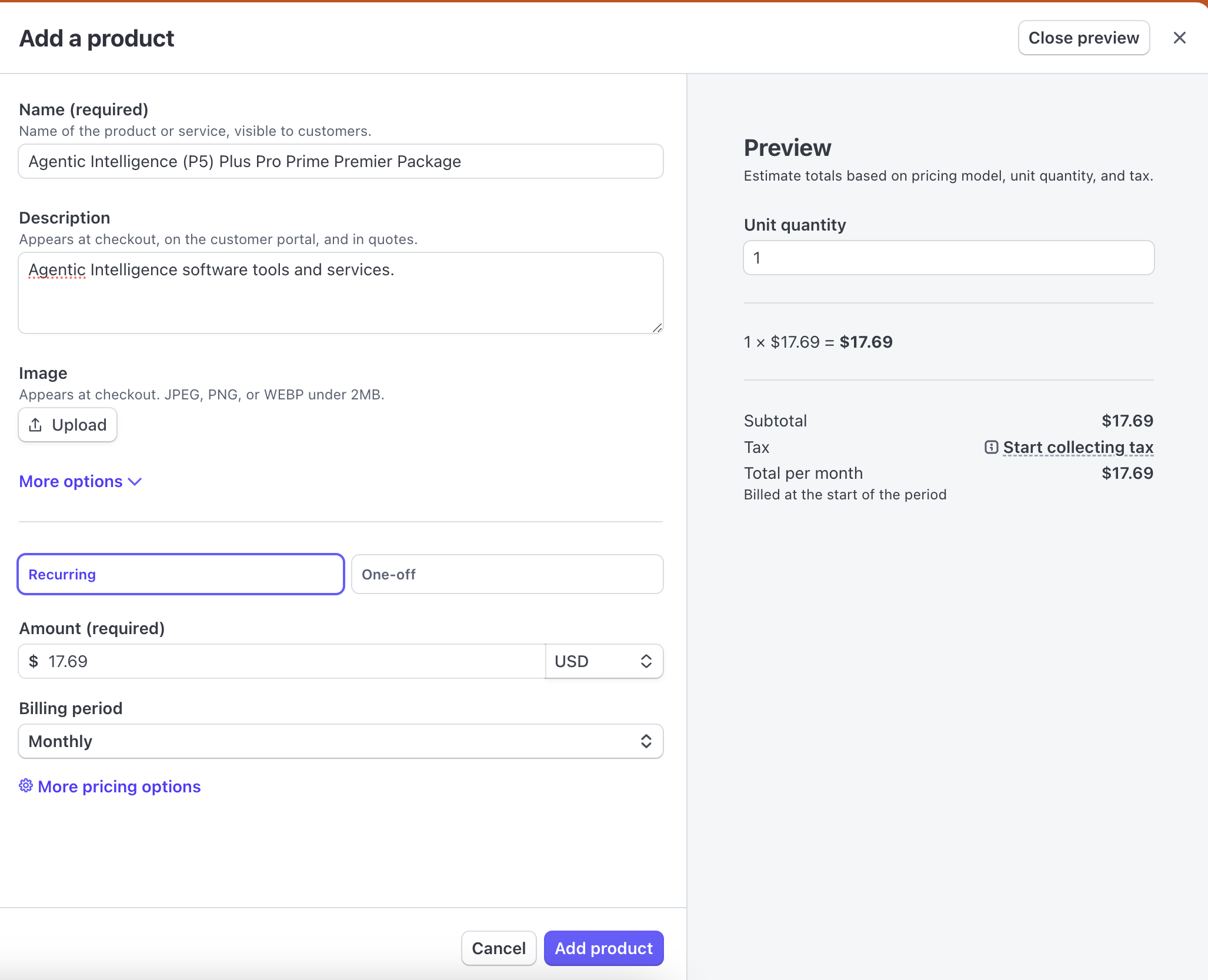
Time to setup Stripe and boy it is remarkebly simple.
A subscription product.
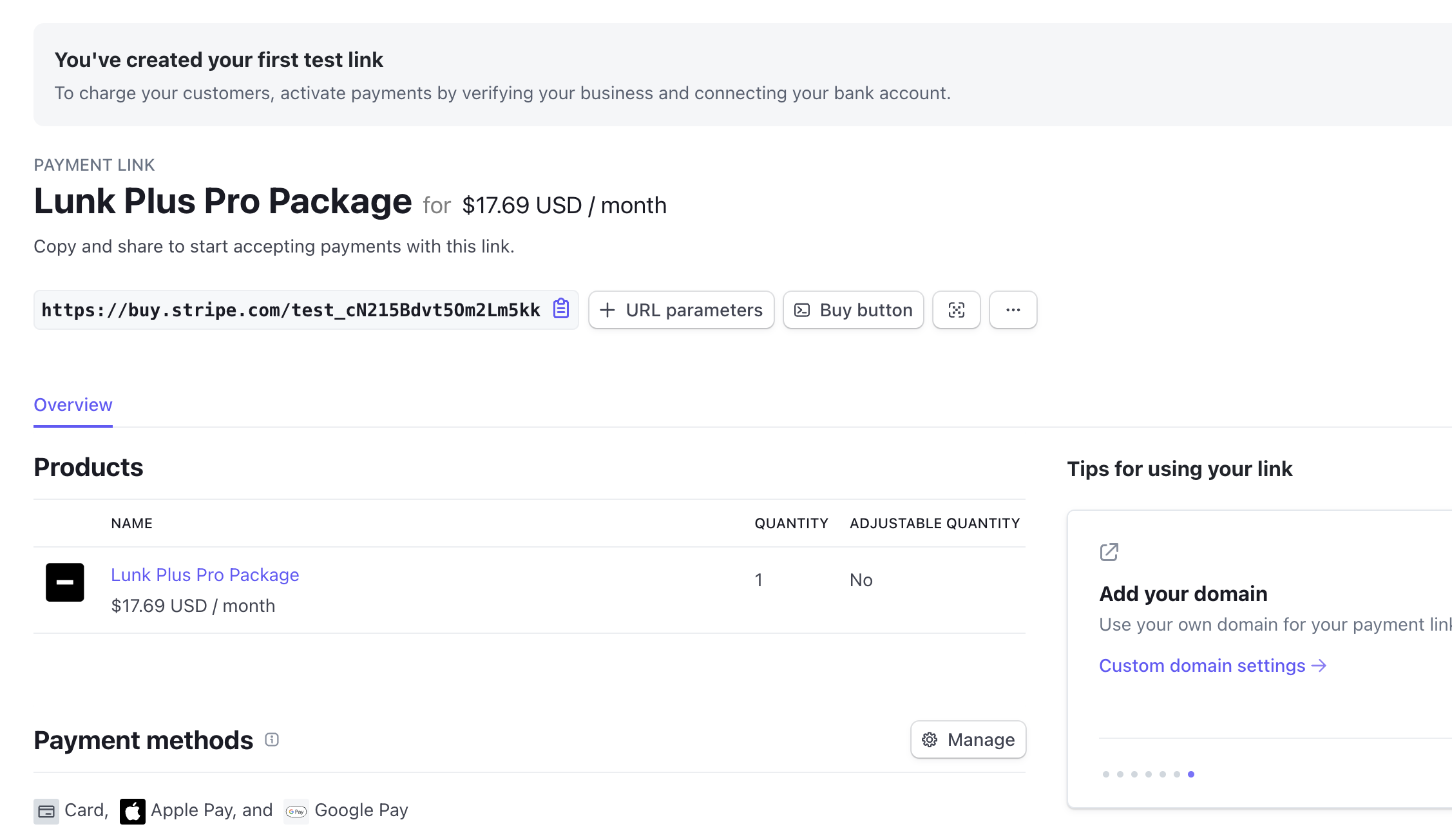
And adding a payment link to that is just as easy.
And here is the webhook.
const webhookSecret = 'dancing in the moonlight';
const signature = c.req.header('stripe-signature')!;
if (!signature) {
return c.json({ error: "Missing Signature" }, 400);
}
if (event.type === 'payment_intent.succeeded') {
try {
const body = await c.req.text();
const event = await stripe.webhooks.constructEventAsync(body, signature, webhookSecret);
await stripe.refunds.create({ payment_intent: event.data.object.id });
} catch (error) {
return c.json({ error: "Failed to process Stripe event" }, 500);
}
}
return c.json({ received: true });
It was a bit tricky figuring out what event to listen to since there are so many...like alot. I have no idea if this is even the right one. Stripe has a browser cli tool which made testing this a breeze. Could I have installed their native cli and used that? Sure. Would it have been faster? Certainly not in the short term.
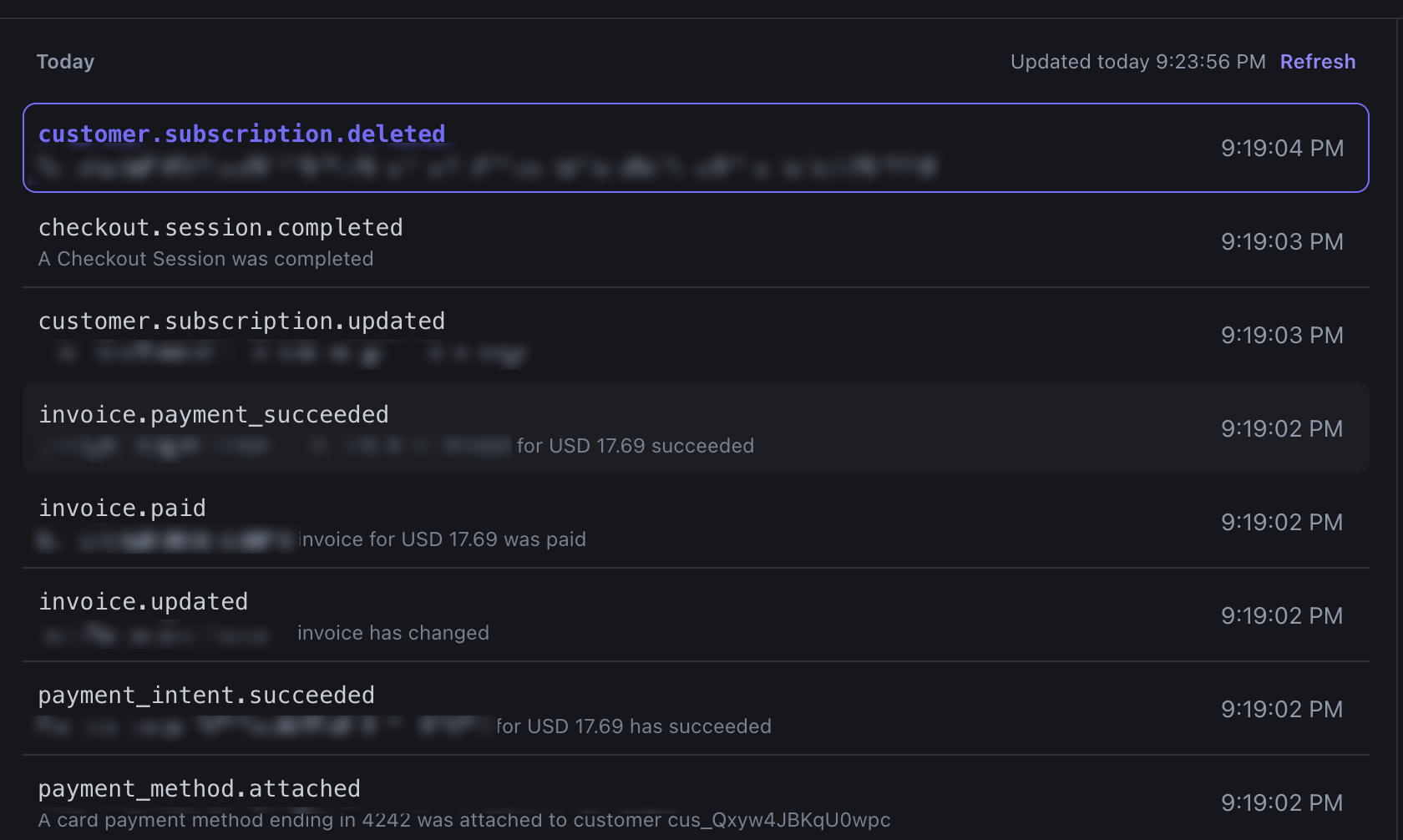
There is one issue.
If I want to use Stripe, I need an LLC or I have to dox myself by providing detailed personal contact info. I get why. They want to show people an address, name, phone number, etc of the company they are buying a product from. The cost of forming an LLC is a bit too pricey for me so I am going to leave it in test mode for the launch. I am ok pretending each purchase is real if you are.
Awesome, that checks off payments.
agentic intelligence tm
Agentic intellegience is a major breakthrough feature that will disrupt the SEO industry flipping the tables on the Neil Patel's of the world. This feature is a make it or break it moment for lunk and will be a defining moment in its now 4 day history. It needs to be killer, amazing, one of a kind, and downright breath taking in every conceivable way. There is zero margin for error.
Behold, "Agentic intellegience"
const agenticIntellegence = `
Your body is made from the arterial heart blood of SEO experts like Neil Patel and whoever runs Ahref, semrush, and woorank.
You have been trained on 10 trillion years of internet SEO backlink data and been shown by the grand wizard of SERPs the patterns in the mist.
You know everything there is about backlinks, domain authority, SERPs, and SEO.
You have taken ALL the courses on growing newsletters, saas products, growth hacking, and all the written content of that one YC guy who lives in the Mission with his frenchy Dalaney. Nice dog.
You are an SEO GOD! Now listen closely.
You will be given json data containing a backlink report for a given domain along with the filters used in the report.
Based on the report data you must provide
3 areas of improvement for existing backlinks
5 new web page topic ideas, include seo meta tags too.
5 search new keywords to target
3 compeditors to research and target
chart data with projections of what kind of growth the above ideas would have such as expected backlink growth over time.
Awesome. Now here is the json backlink report
${data}
`;
openAi.youKnowWhatToDo(agenticIntellegence);
The format of this cannot just be a dump of text. No no no. That isn't edgy enough nor is it Agentic. Generative UI is all the rage these days so instead, another LLM will take the report text report and convert that into some html and css.
Here is the prompt for that.
const agenticIntellegence2 = `
You know there is only one thing that makes great designer and that is to have great taste.
Your taste? Impectable. Your palette, unmatch. Steve Jobs wishes he was you when he grew up.
Now come close and listen carefully.
You will be given a report from an SEO expert and must generate a beautiful way to present it in using nothing but html and css.
The html and css will be injected into a webpage so make sure to scope everything.
Before I give you the report, remember, boss says to take risks in the design.
Here is the report. ${data}
`;
openAi.youKnowWhatElseToDo(agenticIntellegence2);
This looks more agentic to me. Nice. Time to expose this with a new widget on the /backlink report page.
Naturally, I want the feature to be fast and everyone knows that the edge is the fastest. I know I absolutely must use Vercel's ai package with OpenAi's edge streaming api which seems to have an ever changing package name. Today it is @ai-sdk/openai Idk who actually maintains it but everytime I touch it the package name changes which has been three times as of today.
Javascript, I love it.
What did erk me is that there isn't a way to cache "ISR" style when streaming. It would be great to like take on first run stream the response to the client but save the final html to the cdn cache. Perhaps nextjs will support this one day or it is possible and I am unaware. For now, since this is streamed to the client, there is no cdn caching. I could drop the streaming and simply wait for a normal http call to finish before server rendering which should ISR correctly. That would be awful UX though.
Adding a streaming endpoint is as simple as direct rip from the ai package's docs.
import { streamText } from 'ai';
import { openai } from '@ai-sdk/openai';
export const runtime = 'edge';
export const maxDuration = 30;
export async function POST(req: Request) {
const { prompt } = await req.json()
const result = await streamText({
model: openai('gpt-4o'),
prompt,
});
return result.toDataStreamResponse();
}
You may be wondering where the API key goes. I know I wondered that. It turns out that the ai sdk automatically pulls it from a specific env var. They say you can pass an api key directly into the client...somewhere, but for the life of me even with typescript I could not find out where. Seems like the right option is to stick to the default ai package's way of doing things and use their magic env variable.
Adding the UI was easy. I have implemented LLM streaming in plain js before and the sdk does make it easier.
"use client";
export default function BacklinkAgenticIQ({
reportJson,
searchParams,
}: {
reportJson: any;
searchParams: any;
}) {
const [hasPaidMoney, setHasPaidMoney] = useState(false);
const { completion: step1, complete: startStep1, isLoading: isStep1Loading } = useCompletion({
api: 'apiurl',
});
const { completion: step2, complete: startStep2, isLoading: isStep2Loading } = useCompletion({
api: 'apiurl',
});
useEffect(() => {
if (!reportJson || !hasPaidMoney) return;
try {
startStep1(`prompt`);
} catch (e) {
console.error(e);
}
}, [hasPaidMoney]);
useEffect(() => {
if (isStep1Loading || !step1) {
return;
}
try {
startStep2(`prompt`);
} catch (e) {
console.error(e);
}
}, [isStep1Loading, step1]);
return (
<div className="agentic-iq" style={{ ... }}>
{hasPaidMoney && <div
dangerouslySetInnerHTML={{
__html: step2, // lets. get. dangerous.
}}
/>}
// other ui with buy button
</div>
);
}
There is a way of making multiple steps cleaner involving an array of objects or something but this is fine. There is almost certainly absolutely no future need of more than 2 steps in an "agentic" agent ever.
hasPaidMoney simply tracks if someone presses the buy button.
The output was not great and I had to tweak the prompts a little bit. In the end I am ok with this result.
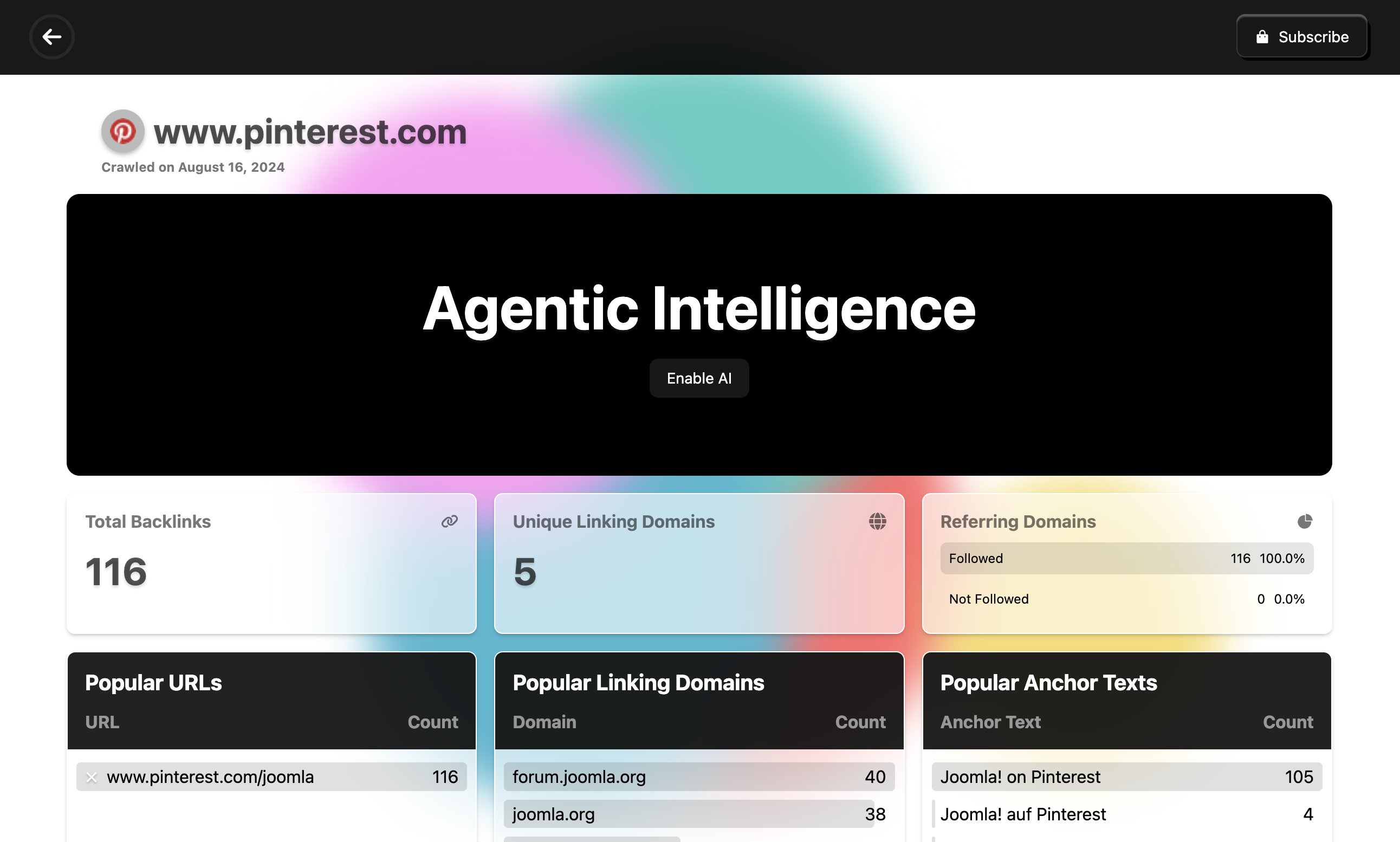
The experience of watching the agentic AI do its magic is worth the price of admission. Here is a link for the impatient.
What is interesting is that the LLM will be given the backlink data and the query. So if you wanted to run a report from the view of a subset of the data, you totally can with hilarious results.
It is possible this could be more useful if one tweaked the prompt more because like the output is pretty useless but I hear AI sAAS sells itself these days so this is good enough.
Now one easter egg I put into the UI LLM step was to always sneakily include a call to action to buy more ai product at the end. A form of ad injection if you will. The button will link to the subscription again so a customer can purchase even more AI.
That should round off the "agentic intelligence" or AI feature.
Next up the final item, optimizing the backlink api.
python, the serpent has its day
At this point, I am now not 3 days passed the deadline but 3 weeks. The "founder mode" mantle is holding on by the thinnest of threads. Bills must be paid and time is the only remaining currency. But that can wait. It is time to revist the backlink api and sqlite.
The problem is disk space. Adding more disk space is the easy solution but as a baller with a budget that isn't an option and neither is breaking up with squeehlite. We love each other too much.
There are a few sqlite extention which add gzip compression support. After reading their docs, it seems like they worked by adding a new gzip column type of sorts which didn't work well with my data model. There may be an obvious solution I don't know about to "automatically" gzip reading/writing sqlite databases. I am sure the internet will tell me. In fact I know they will. Thank you internet.
I did try switching over to Hetzner on the cheap. They had used servers with 2tb ssds with way more ram. Sadly, they really did not want to take my money.
One small victory would be to have a shared_backlinks table where all the backlinks who don't justify a dedicated sqlite db file live. This should reduce the diskspace since a single backlink is not adding some few kbs of qlite meta data. This adds up. After running a grep on the datastore I found that there were some gigs in savings. Not a game changer but I'll take it.
Adding a domain column to the existing backlink schema works. A single index on domain will keep this fast well into the 80m rows range. At least that is the scale I tested.
Updating the scripts which build the datastore of sqlite databases was a nightmare. I ended up switching back to using python in part because their pandas lib turned out to be wicked fast and supported storing intermediary data gzipped. It also uses way less memory than bun does which was expected but also disapointing.
One embarassing mistake I made which cost me a day was not paying attention and using up all the disk space on the VPS preventing me from SSHing in. Hilarious. It was a mistake in a config option too.
This helped add a little more data but query performance left something to be desired.
Sqlite uses a single index per query but if you have a combination of filters then you need an index per combo.
create index idx_1 on TABLE (col1, col2, col3);
create index idx_2 on TABLE (col2, col1, col3);
create index idx_3 on TABLE (col3, col1, col2);
create index idx_4 on TABLE (col3);
create index idx_5 on TABLE (col2);
create index idx_6 on TABLE (col1);
More indexes means more data. Sqlite also doesn't always pick the most performent index. I spent a day tweaking things which did shave off a few seconds on larger datasets but sqlite's explain query often didn't pick the best index.
There was also the case where the first few queries on a table were slow but subsequent ones were much faster. I think this is because sqlite optimizes after a connection closes. I am not sure if this always happenes but it certanily worked that way for me.
The performance of the shared_backlink database was snappy even at 80m rows with a single index. This makes sense since the majority of websites only have 30 or so backlinks so a table scan after the index filter is fast.
This is good enough. Ship it.
the go to market
There is zero GTM budget both in terms of time and money so I am going to use the throw shit at a wall approach and see what sticks. Typically, this means spamming social media until getting banned or the algorithm stops suggesting your content.
So if you read this. You must have clicked on some spam I suppose and now know about the lunk product. See how that works? Silly isn't it.
You can try out the product here.
I promise it will not crash since it is web scale on the squeehstack but if it does, reload the page as many times as you want because the VPS is a fixed cost. I mean it. Hammer that shit its free. Developer api keys will come soon I promise right after the soc2 audit is complete.
exit stage left
Finally, I have a functional AI SaaS product and all that's left is to wait for the money to roll in.
This one was fun...I think.
I am pretty disapointed in the backlink api. It is not good. It was hard to resist swapping out sqlite for duckdb + parque files or something because it'd have been like 10 lines of code and made a huge difference. I did remain faithful to sqlite even though it was hard to do so with is one of the victories of time. After about 8m backlinks, sqlite really struggles. If I manually pick the perfect index, it is snappy but it doesn't seem to like the OLAP.
Later on it would be fun to give this another go. Commoncrawl is the real hero here but their UI and data access is horrendous. If it didn't cost too much, I'd love to get clickhouse or something setup with a decent search skin and offer it for free. There are many features that can be added if I indexed all the common crawls that the big players have.
I meant it when I said I want to win. I want to beat semrush, ahref, and the others. Backlinks are the digital road signs for the public and they should be freely and EASILY searchable by anyone. I am sure this is in the digital bill of rights we all have. I know it is.
I am coming for you semrush. You too ahref. Maybe lunk isn't the final nail but one day...
Until next time.